
Fine-Tuning the Fuzziness of Strong Fuzzy Partitions through PSO
 , Corrado Mencar
, Corrado Mencar- DOI
- 10.2991/ijcis.d.200904.002How to use a DOI?
- Keywords
- Strong fuzzy partition; Trapezoidal fuzzy sets; Fuzzy rule-based classifier; Defuzzification; Particle swarm optimization
- Abstract
We study the influence of fuzziness of trapezoidal fuzzy sets in the strong fuzzy partitions (SFPs) that constitute the database of a fuzzy rule-based classifier. To this end, we develop a particular representation of the trapezoidal fuzzy sets that is based on the concept of cuts, which are the cross-points of fuzzy sets in a SFP and fix the position of the fuzzy sets in the Universe of Discourse. In this way, it is possible to isolate the parameters that characterize the fuzziness of the fuzzy sets, which are subject to fine-tuning through particle swarm optimization (PSO). In this paper, we propose a formulation of the parameter space that enables the exploration of all possible levels of fuzziness in a SFP. The experimental results show that the impact of fuzziness is strongly dependent on the defuzzification procedure used in fuzzy rule-based classifiers. Fuzziness has little influence in the case of winner-takes-all defuzzification, while it is more influential in weighted sum defuzzification, which however may pose some interpretation problems.
- Copyright
- © 2020 The Authors. Published by Atlantis Press B.V.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
The design of fuzzy inference systems promotes interpretability as a key factor to express the embedded knowledge in a plain readable and understandable way. As a matter of fact, interpretability is the most important quality that justifies the adoption of fuzzy inference systems in real-world applications [1,2,3,4]. When such systems have to be acquired through data-driven approaches, two main design issues arise: (i) the resulting fuzzy inference system should adequately fit data; (ii) the knowledge base should be interpretable to end-users. This led to the development of design methodologies that take into account both accuracy and interpretability [5,6,7,8,9,10,11]; in parallel, the very concept of interpretability, its definition and assessment are matter of current research [12,13,14,15].
In this paper we focus on a specific type of fuzzy inference system, namely the fuzzy rule-based classifier, which adopts a knowledge base consisting of a set of fuzzy classification rules in the form
Rule
The interpretation of linguistic terms determines a collection of fuzzy sets: a standard approach to impose interpretability of linguistic variables is to consider such an ensemble of fuzzy sets as a granulation (or fuzzy partition) of the variable domain. In particular, a convenient way to define such fuzzy sets is through strong fuzzy partitions (SFP), i.e., collections of complementary fuzzy sets where the sum of the membership degrees over all fuzzy sets is always equal to the unity, whatever the variable value in the domain. SFPs are convenient tools because they help in satisfying a number of basic interpretability constraints and enable efficient inference since complementarity avoids that many rules are simultaneously active for a given input [20]. Usually, the fuzzy sets of a SFPs are defined through triangular or trapezoidal membership functions, although less common alternatives exist [21,22,23]. In this work we focus on trapezoidal fuzzy sets because they can be efficiently computed and offer greater flexibility than triangular partitions, the latter being considered as a special case.
Typical data-driven design techniques use optimization methods to set the parameters of the fuzzy sets so as to adapt to data. (Eventually, such optimization is constrained to preserve the well-formedness of the involved SFPs.) In most cases, fuzzy sets are optimized in terms of both their position and their fuzziness. The first is related to the sub-regions of the domain where the fuzzy sets mostly influence the inference; the latter indicates how much the fuzzy sets are different from crisp sets. Fuzziness and position can be differently measured [24,25]. For the sake of the present study, position can be defined in terms of 0.5 cut; fuzziness can be defined in terms of the slopes of the oblique slides of the trapezoidal fuzzy sets. In this way, it is possible to well separate position and fuzziness, and analyze them separately.
In this work we address the problem of assessing the impact of fuzziness in the performance of a fuzzy rule-based classifier, provided that its position is kept fixed. We consider this issue to be a very important one because many data-driven design methods mainly focus on position of fuzzy sets, while fuzziness is relegated to a more marginal role. As an example, in some works SFPs are defined by looking at prototypes (often obtained after some optimization process), then fuzzy sets of triangular shape are defined so as to form a SFP [26,27,28,29]: in such a case, the information coming from prototypes actually settles the fuzzy sets position, while the determination of fuzziness is only functional to preserve the well-formedness of the partition.
In a previous work of ours, we showed that trapezoidal fuzzy sets offer more degrees of freedom than triangular fuzzy sets, but they still preserve the well-formedness of SFPs [30]. The adoption of triangular fuzzy sets is therefore self-limiting as it introduces a bias which may hinder the reach of acceptable accuracy levels. On the other hand, trapezoidal fuzzy sets require the setting of more hyper-parameters, therefore some existing design techniques (which compute the prototypes of fuzzy sets) cannot be directly applied. To overcome this problem, data-driven optimization can be split into two steps: optimization of position and fine-tuning of fuzziness. We already proposed two methods for fine-tuning the fuzziness of trapezoidal fuzzy sets [31]. Those methods, however, cannot guarantee that the space of all possible SFPs is thoroughly spanned in search of an optimal solution. In this paper we propose an extension of those methods and we prove that this extension is capable to explore the entire search space. In this way, we are able to empirically assess the effects of fuzziness on the overall accuracy of a fuzzy rule-based classifier (while position is kept unchanged), with different inference settings.
After a brief outline of the related work reported in Section 2, in Section 3 we formally define the concepts of SFPs and trapezoidal fuzzy sets, together with the constraints that such fuzzy sets must fulfill to preserve the well-formedness of a SFP. In Section 4 we introduce PSO and we sketch the way to represent trapezoidal SFPs as particles. In Section 5 we formally prove that the proposed representation allows PSO to span the entire space of SFPs with fixed positions. Section 6 summarizes the experimental results on synthetic and benchmark datasets. Finally, Section 7 concludes the work by highlighting the main results and setting the direction of future research.
2. RELATED WORK
The design of SFPs in fuzzy modeling is long-stated. The simplest design approach is uniform granulation, where the domain of a feature (assumed to be a closed interval in the real line) is partitioned by detecting a number of equally-spaced points in the domain, which eventually serve as prototypes of triangular fuzzy sets. The number of such prototypes is usually user-defined although some computational methods have been proposed in literature for its determination [32].
Noticeably, the position and fuzziness of fuzzy sets determined by uniform granulation do not depend on data: the reasons to use this method are related to the appreciable interpretability of the resulting partitions and the relative difficulty to determine data-driven SFPs with comparable interpretability level. Nevertheless, uniform granulation is too rigid as it does not adapt to data. For such a reason, several methods have been proposed to enable a data-driven design of fuzzy partitions, especially in the realm of evolutionary computation [33].
Starting from some pioneering works on data-driven structure identification of fuzzy rule bases [34], a huge literature developed around the problem of data-driven design of fuzzy partitions [5,35,36,37]. Two general approaches can be identified when attempting to classify data-driven design methods for fuzzy partitions [38]: First Interpretability Then Accuracy (FITA), where fuzzy partitions are first defined (often through uniform granulation) then fine-attuned to data in order to maximize accuracy; First Accuracy Then Interpretability (FATI), where fuzzy partitions are firstly generated from data (often through data clustering) then adjusted to meet a number of interpretability requirements. In most cases, fuzzy sets are adjusted both in their position and fuzziness in order to optimize some objective function.
In some cases, fuzziness is explicitly addressed separately from position. As an example, Alcalá et al. [39] use a particular representation of linguistic terms involving two different parameters expressing the variation of position and fuzziness with respect to a reference SFP. Specifically, fuzziness is quantified as the length of the support of triangular fuzzy sets. These variations are used as parameters to be optimized through a genetic algorithm (GA). Results show that by adjusting both position and fuzziness, the accuracy of the resulting fuzzy rule-based systems can be improved. That is paid in terms of a decreased interpretability since the resulting partitions are no longer strong. Noticeably, the reported experiments show that the introduction of fuzziness optimization leads to a slight improvement with respect to a schema where only position is optimized.
Sanz et al. [40] use GAs for improving the performance of fuzzy rule-based classification systems by adapting the fuzziness of (triangular) fuzzy sets as measured by the length of their support. In this work, interval-valued fuzzy sets are used to represent linguistic terms, and inference depends on lower and upper triangular fuzzy sets that may not satisfy the requirement of SFPs. Also, the use of triangular fuzzy sets only (though of type-2) does not assure that all possible fuzziness degrees are exploited to find the final fuzzy partitions. Nevertheless, experimental results show that accuracy can be improved by acting on the fuzziness of the fuzzy sets.
In many cases, triangular fuzzy sets are used to define the semantics of linguistic terms. In few works, however, trapezoidal fuzzy sets have been employed with the result of a greater flexibility. For example, Nguyen et al. [41] showed that the extension of hedge algebra semantics by trapezoidal fuzzy sets (in place of triangular) leads to an average improvement of the resulting fuzzy rule-based classifiers in terms of both structural complexity and accuracy.
Evolutionary algorithms have been employed to optimize trapezoidal fuzzy sets for data-driven design of fuzzy partitions [42]. However, differently from triangular fuzzy sets, special care must be paid on the way fuzzy sets' parameters are fixed: without proper constraints, it is not guaranteed that the resulting partition satisfies the requirements of a SFP.
The aforementioned research works, alongside subsequent developments, stimulated a research question concerning the evaluation of the influence of the sole fuzziness in the data-driven optimization of a fuzzy partition, given a certain type of fuzzy rule-based system. To conduct this study, an optimization framework is needed with some key features:
the optimization process must operate in the space of fuzziness only, so as to avoid the interference due to changing the position of fuzzy sets. To this purpose, a proper formalization of fuzziness is required;
the optimization process should potentially span all possible values of fuzziness for all the fuzzy sets involved in the fuzzy partitions that constitute the database of a fuzzy rule-based system;
the optimization process must not consider configurations of fuzziness that violate the requirements of SFPs.
The following sections are devoted to illustrate the proposed approach for optimizing the fuzziness in the way declared above. The main assumptions in this work are
we consider fuzzy rule-based classifiers only, with different defuzzification schemes and no rule weights involved. This is the simplest structure of rules that can be useful to highlight the influence of fuzziness in the final quality of the model;
we use trapezoidal fuzzy sets because they are more flexible than triangular fuzzy sets and provide a wider search space in terms of fuzziness. Additionally, fuzziness of trapezoidal fuzzy sets can be easily formalized in terms of the slopes of their oblique slides.
As a final note of caution, we underline how our proposal does not concern a new modeling technique (which would be improper since fuzzy sets are not modified in terms of position), rather it is focused on the analysis of the influence of fuzziness in the performance of the selected models.
3. CUT-BASED REPRESENTATION OF SFPs
With the purpose of separating position and fuzziness of the trapezoidal fuzzy sets involved in a fuzzy partition, we resort to a specific representation that is focused on the crossing points between adjacent fuzzy sets, which are henceforth called cuts.
Let
For

A strong fuzzy partition (SFP) over the Universe of Discourse composed by 5 fuzzy sets whose positions are determined by the arrangement of 4 cuts.
Different types of fuzzy sets can be involved into the realization of a SFP; among them, the trapezoidal fuzzy sets are characterized by a four-parameter function
Indeed, the choice of the fuzzy set typology is significant in our research. Since we are dealing with the problem to design SFPs constrained by cuts, it is worth recalling that the employment of triangular fuzzy sets is a limiting choice, which would lead to the impossibility to produce triangular SFPs when some particular sequences of cuts are assigned. The adoption of trapezoidal fuzzy sets, instead, is flexible enough to guarantee the realization of well-formed SFPs whatever sequence of cuts is assigned, as demonstrated in a previous work of ours [30].
The fuzzy sets involved in a trapezoidal SFP must be such that
To tailor a trapezoidal SFP to an assigned sequence of cuts
The conditions expressed in (3) allow the cut
Several methods may be adopted to build a trapezoidal SFP from cuts. The Constant Slope (CS) method [30] is a very simple and intuitive one, which can be applied in full compliance with the aforementioned conditions (2–3). According to the CS method, a common slope is set for all the trapezoidal fuzzy sets involved in the resulting SFP. This specific slope is the one1 associated to the sides of the triangular fuzzy set centered on the middle point between the nearest cuts in the assigned sequence. Figure 2 illustrates an application of the CS method: the sequence of cuts

A trapezoidal strong fuzzy partition (SFP) tailored on the basis of 3 assigned cuts through the application of the constant slope (CS) method.
Other methods can be adopted to derive trapezoidal SFPs from cuts: each of them is supposed to provide different results [30]. All of the partitions are characterized by a number of trapezoidal fuzzy sets with fixed positions (due to the prearranged sequence of cuts) and exhibit dissimilar fuzziness as determined by the different slope configurations of the oblique slides. However, a single method is able to produce a single partition of fuzzy sets, against a number of possibilities which is infinite. Hence the necessity to devise a way for fully exploring this space of possibilities to properly investigate how fuzziness affects the performance of such SFPs when they are applied in some contexts of application.
4. PARTICLE SWARM OPTIMIZATION AS A TOOL TO OPTIMIZE FUZZINESS
Particle swarm optimization (PSO) is a computational method devised to perform stochastic optimization [43]. Originally introduced in 1995 [44], it soon started attracting interest from researchers and underwent further analysis, variations, and development [45,46,47,48].
PSO emulates social behavior with special references to such organized groups as insect swarms, fish schools, and bird flocks. All of them are composed by a large number of individuals which all together interact and coordinate their movements to contribute to the global repositioning of the group. In this way, the whole set of individuals is able to reach some goal of common interest. Drawing inspiration from this natural behavior, PSO incorporates a number of entities moving through a search space to find a (nearly-)optimal solution for a given problem. Movement and velocity are key concepts, so the involved entities are called “particles,” a term which best suits these notions. Just like in a flock or a swarm, the particles interact with one other and, at the same time, they learn from their own experience. To keep track of advancements, PSO evaluates the particles' positions through an objective function (which must be minimized) and then moves the population at each successive iteration of the process. The movement of each particle through the search space is determined by combining information about its current and best position, the best positions reached by one or more other particles in the swarm, and some random perturbations. As a global result, the population gradually moves toward better regions of the search space, reaching a final position which can be regarded as the solution of the problem at hand.
Given an objective function
By the term “best” position, we refer to the evaluation of a position vector performed through the objective function, which is purposely designed depending on the problem at hand.
The PSO is organized as an iterative process: at each step, the position and velocity vectors of each particle are updated as follows:2
To some degree, the PSO working machinery resembles another nature-inspired algorithm, i.e., the GA, which is also a stochastic population-based optimization process. Both particles and chromosomes similarly act as candidate solutions and the objective function in PSO clearly recalls the fitness function of GAs. However, some differences between these methods can be highlighted [49]. PSO does not implement selection and lacks genetic operators such as crossover and mutation (even if a kind of crossover is represented by the combined information of particle and neighborhood best positions, useful to evaluate acceleration). Also, PSO is intrinsically directional in its process, while the GA mutation is omnidirectional in its nature. All in all, PSO is able to produce satisfactory results in terms of optimization while showing the benefit of an easier implementation and a reduced number of parameters to adjust when compared with GA. It applies, therefore, as a suitable candidate to carry on the exploration of the search space we are going to investigate in the present work.
The scenario under study is such that the SFPs are meant to be exploited to build up a fuzzy rule-based inference system from data. Therefore, we deal with the following setting:
the cuts are supposed to be imposed by the specific context and derived from the analysis of the dataset at hand (by means of a particular clustering process);
the objective function steering the PSO process is represented by the average accuracy obtained while evaluating the rule base corresponding to the derived SFP;
the particles' position in the search space must be related to the shape of trapezoidal fuzzy sets.
It can be observed how, according to (a), the locations of the involved trapezoidal fuzzy sets are fixed in our setting.
We already applied PSO to design trapezoidal SFPs in a preliminary study of ours [31]. In particular, concerning point (c), we put a direct correspondence between the particles and the edges of a trapezoidal fuzzy set. More precisely, given a sequence of cuts
Moving from those assumptions, it is straightforward to consider an
Since the sequence of cuts
Therefore, we developed a couple of strategies to constrain the placement of the
The results we obtained were encouraging, however we were conscious that the imposed constraints reduced the search space as a side effect. In other words, during the PSO process the particles could not explore all the infinite possible solutions of the problem at hand, but a subset of them (which is different depending on the specific strategy adopted to constrain the ranges
5. A NEW DEFINITION OF THE PSO SEARCH SPACE
The preliminary tests showed that PSO stands as a suitable tool to support the design of SFPs based on cuts. However, to fully appreciate the effectiveness of this approach, a thorough exploration of the search space must be performed. In this way, we can evaluate how much the PSO algorithm is able to fine-tune the fuzziness of the fuzzy sets involved in an inference system whose realization is constrained by some assigned cuts. In this section, therefore, we introduce a novel formalization of the particles involved in the PSO process and we demonstrate that it is instrumental in shaping a search space including all (and only) the trapezoidal SFPs possibly standing on a UoD.
To this aim, we alter the meaning of the particle positions in the search space: instead of being regarded as the set of edges
To derive the edges of the fuzzy sets, we proceed as follows. Assigned a sequence of cuts
It can be observed how all the points
Figure 3 provides an intuitive understanding of the


Placement of
Moving from the above assumptions, we are going to demonstrate that, as the values
Firstly we must consider the following lemmas:
Lemma 1
Let
Proof.
From being
From (11a) we obtain
On the other hand, from (11b) we obtain
Proof.
For
For
Whenever
Theorem 3
Let
Proof.
To construct a well-formed trapezoidal SFP the following relationship must hold:
From Lemma 2 we argue that
In summary, the relationship (15) is proven and we can argue that, however set the values of
Theorem 4
Let
Proof.
If the values of
However, the inequality in (16b) contrasts with (15), thus ruining the well-formedness of the resulting trapezoidal SFP. Concerning the inequality in (16a), from being
The inequality in (17a) again contrasts with (15). The inequality in (17b) implies
We have shown that by varying the values of
It can be observed that the parameters
6. EXPERIMENTAL RESULTS
Trapezoidal SFPs may be useful to design the structure of inference systems based on fuzzy rules. We already mentioned how this idea has been injected in the very definition of the previously discussed PSO algorithm, whose objective function is represented by the accuracy evaluation of the resulting fuzzy system applied on some dataset. The cuts themselves can be interpreted as constraints intrinsic to the problem at hand, which can be extracted from the dataset analysis. In our work, we are not interested in tackling some specific problem aiming at designing an optimal fuzzy inference engine to solve that particular task at its best. Our goal is to test the suitability of the developed PSO strategy in fine-tuning the design of trapezoidal SFPs based on cuts, instead. To this aim, we refer to a number of datasets related to classification problems: we are going to use them to evaluate the performance evolution of some fuzzy rule-based systems while optimizing the fuzziness of the fuzzy sets involved in the underlying fuzzy partitions.
We set up an array of datasets, including both synthetic and real benchmark data. The first are described in Table 1: they are all bi-dimensional datasets purposely designed to include a diverse number of samples and classes. The benchmark datasets are described in Table 2: they come from publicly accessible repositories and can be retrieved online. [50,51,52]. Again, they represent a variety of cases in terms of samples, features, and classes.
| Dataset | # Samples | # Features | # Classes |
|---|---|---|---|
| 200 | 2 | 3 | |
| 400 | 2 | 3 | |
| 400 | 2 | 3 | |
| 300 | 2 | 3 | |
| 600 | 2 | 3 | |
| 500 | 2 | 2 | |
| 300 | 2 | 2 | |
| 600 | 2 | 3 |
Description of the synthetic datasets involved in the experimental session.
| Dataset | ID | #S | #F | #C |
|---|---|---|---|---|
| Appendicitis | Ap | 106 | 7 | 2 |
| Balance | Bl | 625 | 4 | 3 |
| Banana | Bn | 5300 | 2 | 2 |
| Beer Styles | BS | 400 | 3 | 8 |
| Bupa | Bu | 345 | 6 | 2 |
| Cardiotocography | CTG | 2126 | 21 | 3 |
| Hayes-Roth | Hy | 160 | 4 | 3 |
| Ionosphere | Ion | 351 | 33 | 2 |
| Iris | Ir | 150 | 4 | 3 |
| Monk-2 | Mo | 432 | 6 | 2 |
| Newthyroid | Nth | 215 | 5 | 3 |
| Page-Blocks | PB | 5472 | 10 | 5 |
| Phoneme | Ph | 5404 | 5 | 2 |
| Pima | Pi | 768 | 8 | 2 |
| Saheart | Sh | 462 | 9 | 2 |
| Sonar | So | 208 | 60 | 2 |
| Thyroid | Thy | 7200 | 21 | 3 |
| Vertebral 2 | V2 | 310 | 6 | 2 |
| Vertebral 3 | V3 | 310 | 6 | 3 |
| Wine | Wi | 178 | 13 | 3 |
Description of the benchmark datasets involved in the experimental session. (#S = number of samples, #F = number of features, #C = number of classes.)
The cuts needed to trigger the design process can be acquired directly from data by means of a clustering process. In particular, we employed DC*, an algorithm which takes its name from Double Clustering with A*, i.e., a mechanism oriented to extract interpretable information from data [53]. That is accomplished by going through a two-step process which firstly clusters the data around some detected prototypes and then projects the prototypes themselves along each feature axis to allow a further clustering performed by the A* algorithm. By doing so it is possible to derive a partition over each dimension: this represents the setting where the SFPs can be grounded, thus enabling the design of a fuzzy rule-based system incorporating the fuzzy sets which compose the obtained fuzzy partitions. This process is carried out by the DC* algorithm intervening on every dimension at the same time: some of them could be unaffected by the partition construction, thus implicitly reducing the dimensionality of the problem at hand. The interested reader can find a thorough description of DC* in Ref. 53.
The cuts play a pivotal role in the previously described algorithm since they represent the mid-points placed on each axis between a couple of projections referring to prototypes of different classes. As such, they contribute to the definition of the final configuration of partitions: a subset of cuts is identified through the A* search to split the space of the problem into sub-spaces containing homogeneous prototypes.
For the purposes related to the present work we are going to exploit DC* not to benefit of its main results (namely, the definition of interpretable granules of information to be embedded into an inference engine in form of fuzzy rules), but to profit from its side products, i.e., the cuts derived from data. As previously asserted, they are necessary to start up the trapezoidal SFP optimization process. In this sense, we are not concerned with the attainment of the best clustering results which DC* may provide. For that reason, in some cases we contented with sub-optimal cut configurations. That can be noticed by referring to Figure 4 where the datasets

Graphical representation of the synthetic datasets adopted for the experimental session. The figures include the cuts produced by DC*.
Once the cuts are assigned, an infinite number of partitions can be drawn on the space of data. To assess the capability of the PSO algorithm as a fine-tuning tool of trapezoidal SFPs, we firstly set a landmark method to be employed in the following for the sake of comparison. That is represented by the CS algorithm described in Section 3, which is one of the default methods adopted by DC* to finally produce the trapezoidal fuzzy sets composing the fuzzy inference system resulting from the data clustering process. We launched the PSO algorithm following the scheme reported in Equation (5), posing
A twofold inference strategy has been set up to assess the performance of the fuzzy systems built up on the SFPs obtained through the CS method. On the one hand, a winner-take-all strategy (labeled as “
Tables 3 and 4 illustrate a comparison (in terms of accuracy performance) of the fuzzy rule-based systems resulting from the partitions obtained by the CS method and the PSO full search (FS). The comparison refers to the classification of the synthetic data applying the
| Dataset | Accuracy Performance (%) | Accuracy | |
|---|---|---|---|
| CS | FS | gain (%) | |
| 82.00 | 82.00 | 0.00 | |
| 96.25 | 96.25 | 0.00 | |
| 81.75 | 95.00 | 13.25 | |
| 55.33 | 60.00 | 4.67 | |
| 88.17 | 88.50 | 0.33 | |
| 68.00 | 70.40 | 2.40 | |
| 66.67 | 66.67 | 0.00 | |
| 58.67 | 58.67 | 0.00 | |
Fuzzy classification of synthetic data — Fine-tuning operated by the PSO search with respect to CS using the
| Dataset | Accuracy Performance (%) | Accuracy | |
|---|---|---|---|
| CS | FS | gain (%) | |
| 82.00 | 82.00 | 0.00 | |
| 86.75 | 96.25 | 9.50 | |
| 92.50 | 92.75 | 0.25 | |
| 55.33 | 60.00 | 4.67 | |
| 87.67 | 91.33 | 3.67 | |
| 69.00 | 77.40 | 8.40 | |
| 61.33 | 67.67 | 6.33 | |
| 58.17 | 61.67 | 3.50 | |
Fuzzy classification of synthetic data — Fine-tuning operated by the PSO search with respect to CS using the
| Dataset | Accuracy Performance (%) | Accuracy | |
|---|---|---|---|
| CS | FS | gain (%) | |
| Ap | 82.08 | 82.08 | 0.00 |
| Bl | 66.08 | 66.08 | 0.00 |
| Bn | 67.30 | 67.32 | 0.02 |
| BS | 95.00 | 95.50 | 0.50 |
| Bu | 61.45 | 62.32 | 0.87 |
| CTG | 75.82 | 75.82 | 0.00 |
| Hy | 44.38 | 44.38 | 0.00 |
| Ion | 65.24 | 65.24 | 0.00 |
| Ir | 88.00 | 90.00 | 2.00 |
| Mo | 36.11 | 36.11 | 0.00 |
| Nth | 92.56 | 92.56 | 0.00 |
| PB | 85.31 | 85.64 | 0.33 |
| Ph | 61.01 | 62.56 | 1.55 |
| Pi | 62.11 | 62.11 | 0.00 |
| Sh | 63.64 | 64.29 | 0.65 |
| So | 56.73 | 56.73 | 0.00 |
| Thy | 91.22 | 91.22 | 0.00 |
| V2 | 56.13 | 56.13 | 0.00 |
| V3 | 72.26 | 72.26 | 0.00 |
| Wi | 81.46 | 81.46 | 0.00 |
Fuzzy classification of benchmark data — Fine-tuning operated by the PSO with respect to CS using the
| Dataset | Accuracy Performance (%) | Accuracy | |
|---|---|---|---|
| CS | FS | gain (%) | |
| Ap | 86.79 | 86.79 | 0.00 |
| Bl | 66.08 | 66.08 | 0.00 |
| Bn | 65.34 | 68.81 | 3.47 |
| BS | 95.25 | 96.00 | 0.75 |
| Bu | 56.23 | 64.93 | 8.70 |
| CTG | 82.03 | 82.08 | 0.05 |
| Hy | 44.38 | 44.38 | 0.00 |
| Ion | 68.95 | 68.95 | 0.00 |
| Ir | 72.00 | 95.33 | 23.33 |
| Mo | 36.11 | 36.11 | 0.00 |
| Nth2 | 83.26 | 92.56 | 9.30 |
| PB | 87.63 | 87.81 | 0.18 |
| Ph | 60.16 | 66.47 | 6.31 |
| Pi | 55.60 | 63.28 | 7.68 |
| Sh | 65.15 | 67.10 | 1.95 |
| So | 53.85 | 58.17 | 4.33 |
| Thy | 93.51 | 93.56 | 0.04 |
| V2 | 49.68 | 57.42 | 7.74 |
| V3 | 62.26 | 78.06 | 15.81 |
| Wi | 68.54 | 87.08 | 18.54 |
Fuzzy classification of benchmark data — Fine-tuning operated by the PSO with respect to CS using the
As a general remark, we can observe the suitability of the PSO algorithm as a tool for fine-tuning the derived SFPs based on cuts. In fact, in several cases its application contributes to modify the fuzziness of the involved fuzzy sets in such a way that the performance of the resulting classifiers is improved when compared to the results related to the baseline CS method. For some datasets the accuracy gain appears to be quite considerable. Also, none of the experiments determined a decay in the classification accuracy. It should be stressed, however, that the goal of our experiments concerned the analysis of the fuzziness influence on the final performance, instead of the definition of the best single model to be employed as an optimal classifier. In other words, we did not perform model selection; that is the reason why we did not apply any scheme of cross-validation, as it is usually the case in some other common experimental sessions whose scope is quite different from ours.
As a further remark, if we consider the results reported in the tables, it is straightforward to argue that the application of the PSO algorithm is much more profitable when fuzzy classifiers equipped with the
In this sense, the main contribution to the final performance of the fuzzy classifiers comes from the position of the fuzzy partitions (which in our experimental session has been fixed by the cuts obtained from data through the application of the DC* algorithm). On the other hand, the performance of the
As a consequence, to fully exploit the contribution coming from the fuzziness component, it makes sense to combine the adoption of the
Finally, to explicitly illustrate the tuning process, Figures 5 and 6 depict the comparison of the trapezoidal SFPs derived for some datasets through the application of the baseline CS method and the PSO algorithm. Particularly, the figures illustrate the results concerning a selected subset of synthetic and benchmark datasets, respectively.

Comparison of the trapezoidal SFPs obtained through the application of the CS (upper row) and FS (lower row) methods. The involved synthetic datasets:
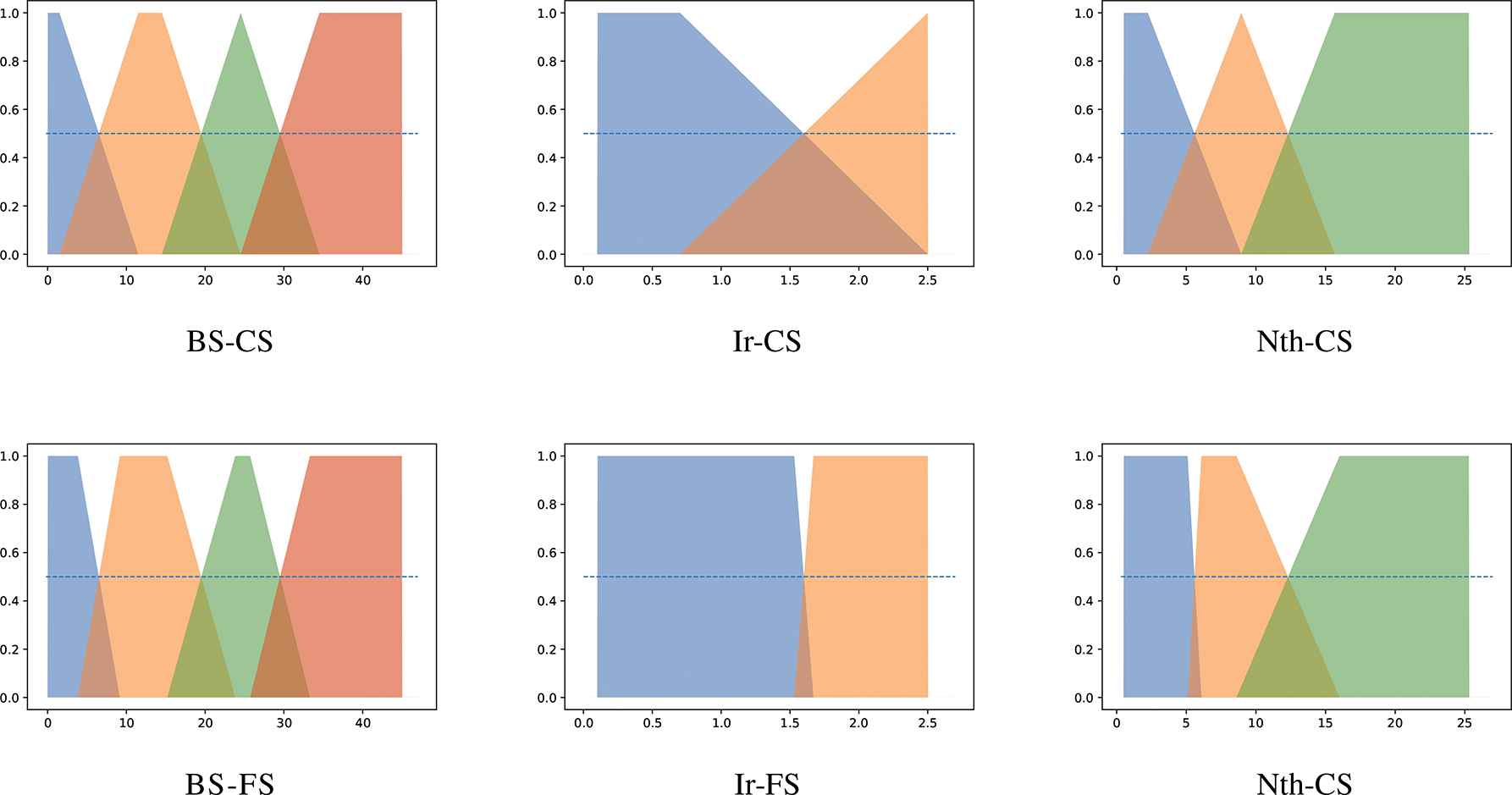
Comparison of the trapezoidal SFPs obtained through the application of the CS (upper row) and FS (lower row) methods. The involved benchmark datasets: BS (
7. CONCLUSIONS
Designing fuzzy classifiers is a challenging endeavor involving a number of research issues. We deal with this matter by analyzing some convenient way to define the SFPs which underlie a fuzzy inference system. Particularly, we highlighted a couple of features that characterize the design of the fuzzy sets involved in a SFP, namely their position and fuzziness. While focusing on a specific shape among others, i.e., trapezoidal fuzzy sets, we investigated the contribution coming from fuzziness when the performance of fuzzy classifiers is evaluated. To this end, we set up an optimization method based on the PSO algorithm to fine-tune the slopes of trapezoidal sets.
We described a mechanism to model the fuzzy sets by adopting a particular PSO implementation: we formally demonstrate that our proposal enables an exhaustive exploration of the search space composed by all the possible SFPs traceable on a UoD once the position of fuzzy sets is fixed. In other words, we were able to provide a thorough assessment of the fuzziness contribution to the performance of fuzzy classifiers. In this sense, this work represents a completion of some previous research of ours, where the PSO algorithm has been adopted to provide a partial exploration of the above-described search space. Additionally, the experimental session allowed to bring into focus some interesting issues which can be of some relevance for the research community working on the design of fuzzy inference system. This kind of remarks are connected to a couple of inference methods which may be adopted to trigger the classification process of a fuzzy system: we termed them
As a hint for future research, we address the theoretical investigation of such inference methods as a major issue to better understand the semantics behind the working engine propelling a fuzzy classifier.
CONFLICT OF INTEREST
The authors declare no conflict of interest.
AUTHORS CONTRIBUTED
All authors read and approved the final manuscript.
ACKNOWLEDGMENTS
The research is partially supported by Ministero dell'Istruzione, dell'Università e della Ricerca (MIUR) under grant PON ARS01_00141 “CLOSE.” The authors are members of the INdAM Research group GNCS.
Footnotes
Actually, two opposite slopes are involved (related to the ascending and the descending sides of the fuzzy set, respectively) which are equal in magnitude.
As previously asserted, some other formulations for updating the PSO vectors have been proposed in literature, but we can refer to this version for our purposes.
Up to now, we considered the SFP which can be drawn on a single UoD. When dealing with real-world problems, the related datasets usually involve several dimensions (say,
REFERENCES
Cite this article
TY - JOUR AU - Ciro Castiello AU - Corrado Mencar PY - 2020 DA - 2020/09/17 TI - Fine-Tuning the Fuzziness of Strong Fuzzy Partitions through PSO JO - International Journal of Computational Intelligence Systems SP - 1415 EP - 1428 VL - 13 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.200904.002 DO - 10.2991/ijcis.d.200904.002 ID - Castiello2020 ER -